I am a Physics PhD student at UTD working in Dr. David J. Lary’s group. Overall our research touches several spaces, but overall has a few common themes: public service, remote sensing, and machine learning. My main focus is quantifying environmental impacts on cognitive load and performance using a comprehensive suite of environmental and biometric variables coupled with various computational tools.
Experience with HPC:
I have never used an HPC system before
My Workflow:
I typically use my personal machine for most work. For more demanding tasks, I will use ssh to access more capable computational resources. About 85% of the time I use MATLAB and Python for the other 15%. When transferring between systems, I typically scp code and data from my personal machine to a beefier machine.
Challenge:
Having a database where all data can be stored, backed up, and easily accessed for analysis. Additionally, access to computational resources for expensive data preprocessing .
I’m fairly familiar with your python and MATLAB workloads in general from my other work with your group. MATLAB is available on europa as of two days ago on the compute nodes.
$ srun -N1 --pty /bin/bash # interactive job to one node
$ ml load matlab # load the matlab module
$ matlab
and python is available in the miniconda module
$ ml load miniconda
From there, you’ll want to create your own virtual enviroments to work with
If you have any problems getting going, let us know.
Now let’s talk about your data. How are you storing your data? How much data are you looking to process and how much do you need to store per job/ per campaign, and how do you store the data after it is processed / how much is retained?
How are you storing your data?
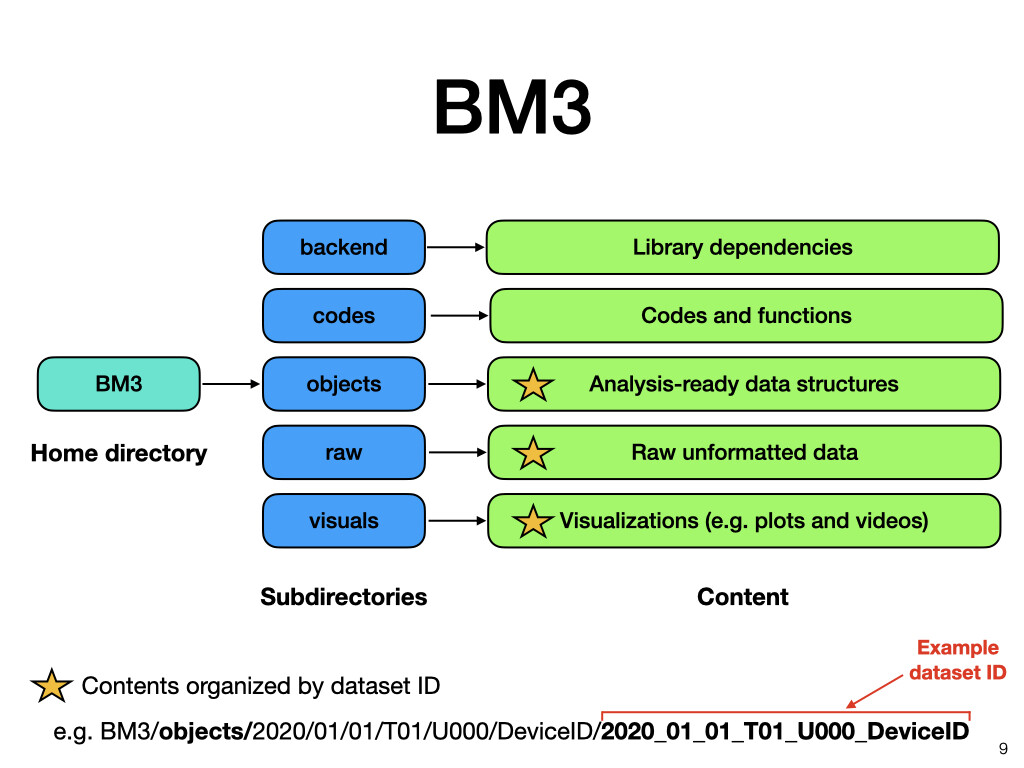
Currently data is stored in several places including: my personal machine, a group NAS device, Box, and a group machine called Air930. The “master” data repository is our NAS device which is backed up on Box. Data is organized by Year, Month, Day, Trial number, and Participant ID. Please see attached photo for a schematic.
How much data are you looking to process and how much do you need to store per job/ per campaign?
One minute of raw data is on the order of 500MB. After processing this increases to about 2GB. A couple of the processing steps are computationally expensive, but can be distributed to multiple workers. Another processing step creates video visualizations which can go up to about 3 GB .avi files for a minute of recording.
How do you store the data after it is processed?
Pre-processed and post-processed data are stored in the same way with the only difference being the root directory name.
Great explanation of your data and your data workflow. Thanks!
I think one of the first things we should do for the MINTS project in general is try to get the data centralized and some form of versioning / metadata capture as well. I have a few ideas on how to do this and I do have a few proposals in motion to try to help with this, but let’s see what we can in the meantime.
How much total data do you (just your part of the project, not the project as a whole) have now and have much will you generate over say the next 2 years?

 .
.